6.6 KiB
The emergence of consensus in Python
Julien Palard
PyCon Fr 2018
There should be one
-- and preferably only one --
obvious way to do it. (Tim Peters)
The emergence of consensus in Python
This is a study about undocumented consensus in the Python community, so you don't have to do it.
Julien Palard
- Python documentation translator
- Teaching Python at
- Sup'Internet
- CRI-Paris
- Makina Corpus
- …
- julien@python.org, @sizeof, https://mdk.fr
- Yes I write Python sometimes too…
Julien Palard
Digression
In one year, we went from 25.7% translated to 30% translated!
While japanese translation is at 79.2% and korean 14.6%.
Notes: Want news about the translation?
Thanks to Christophe, Antoine, Glyg, HS-157, and 27 other translators!
PLZ HELP
What did I do?
Crawled pypi.org to get some Python projects, cloned their github repo (around 4k repositories at the time of writing).
Then... played with the data ^^.
But why?
To answer all those questions a human or a search engine won't be able to answer.
Notes:
- For my README, should I use
rstormd? - unittest, nose, or pytest?
setup.py,requirements.txt,Pipfile, ...?- ...
Is it data science?
Hell no! It's biased, I only crawled projects published on pypi.org AND hosted on github.com, so I'm hitting a very specific subset of the population.
Note:
I mean
- me: Hey consensus is to use the MIT license!
- you: You crawled only open source projects...
- me: Oh wait...
Digression
I used Jupyter, if you still don't have tried it, please take a look at it.
Meta-Digression
If you're using Jupyter Notebook, and never tried Jupyter Lab, please try it.
JupyterLab will replace Jupyter notebooks, so maybe start using it.
pip install jupyterlab
jupyter-lab
Notes:
I know you like digressions, so I'm putting digressions in my digression so I can digress while I digress.
Meta-Digression
10 years of data
I do not have enough data past this so graphs tends to get messy.
stats = raw_data.loc['2008-01-01':,:].resample('6M')
Notes: While Python is 28 years old (older than git, than github, even than Java).
Digression (again)
I used Pandas, if you never tried it...
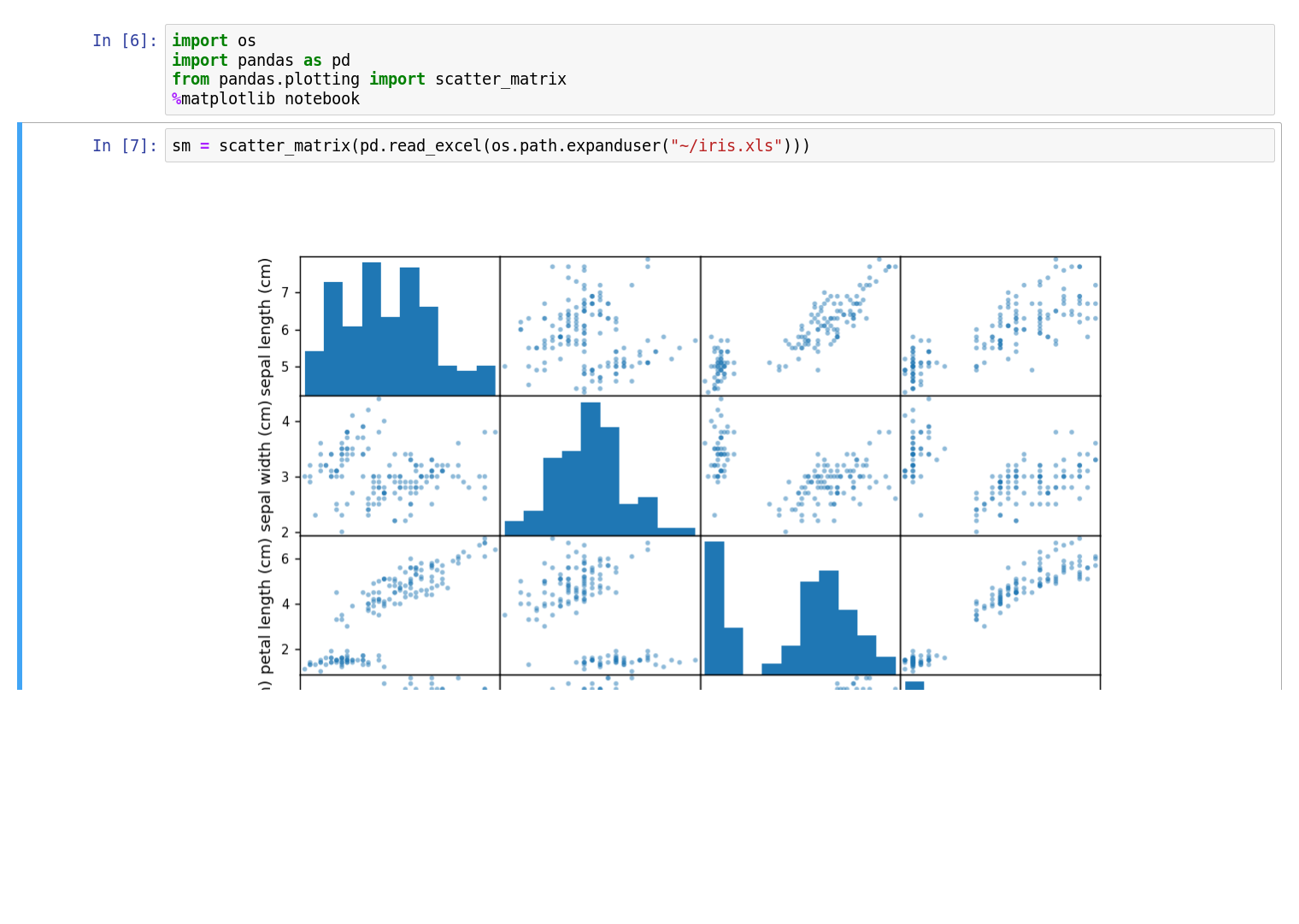
Notes: It's a matrix of scatter plots.
README files
readmes = (stats['file:README.rst',
'file:README.md',
'file:README',
'file:README.txt'].mean().plot())
README files
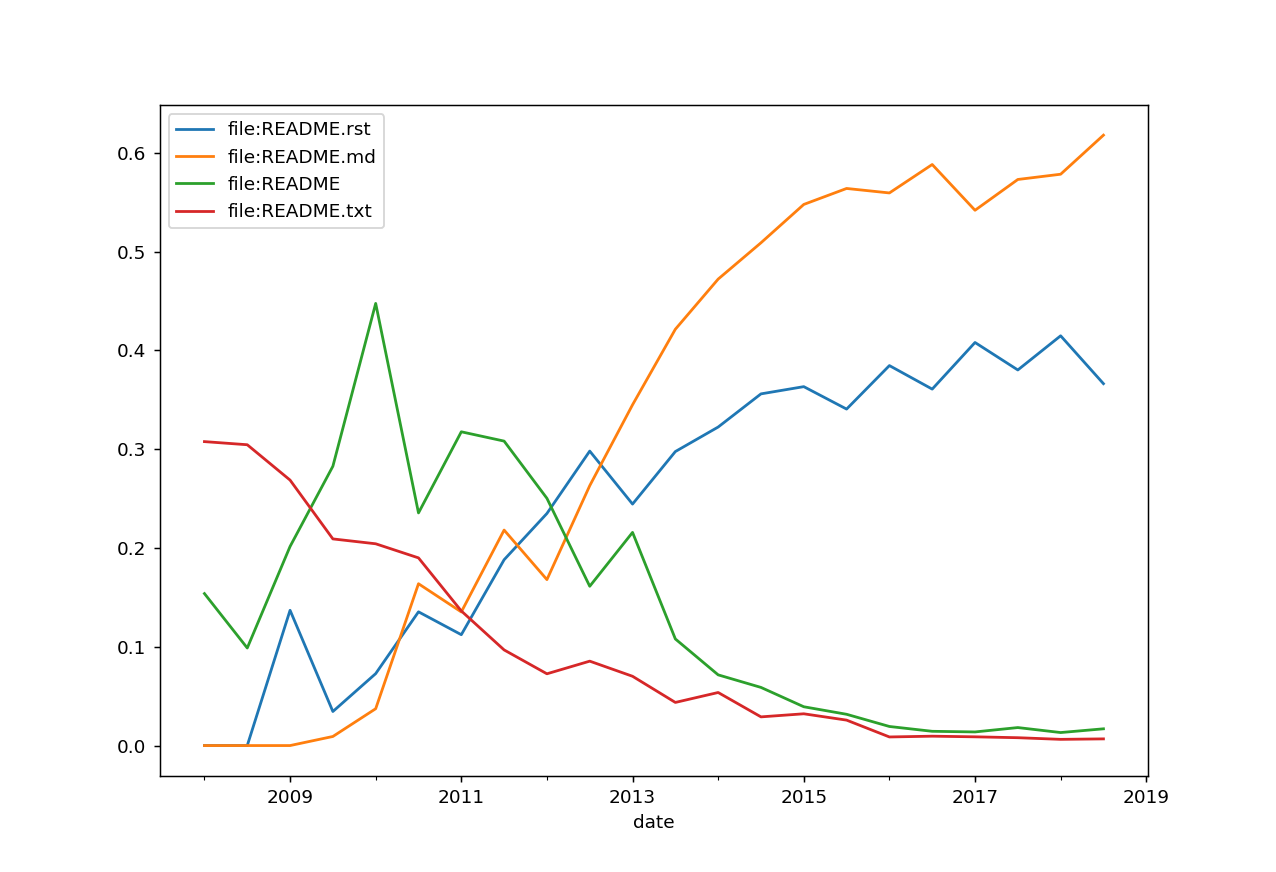
Notes:
Consensus
10 years ago, people used README and README.txt.
It changed around 2011, now we use README.md and README.rst files.
Markdown won. I bet for its simplicity, readability, and also
people may know it from elsewhere.
Consensus
But pypi.python.org don't support Markdown!
Yes, but...
Consensus
pypi.org does!
long_description_content_type='text/markdown'
See:
https://pypi.org/project/markdown-description-example/
So use README.md files!
Requirements
setups = stats['file:setup.cfg',
'file:setup.py',
'file:requirements.txt',
'file:Pipfile',
'file:Pipfile.lock'].mean().plot()
Requirements
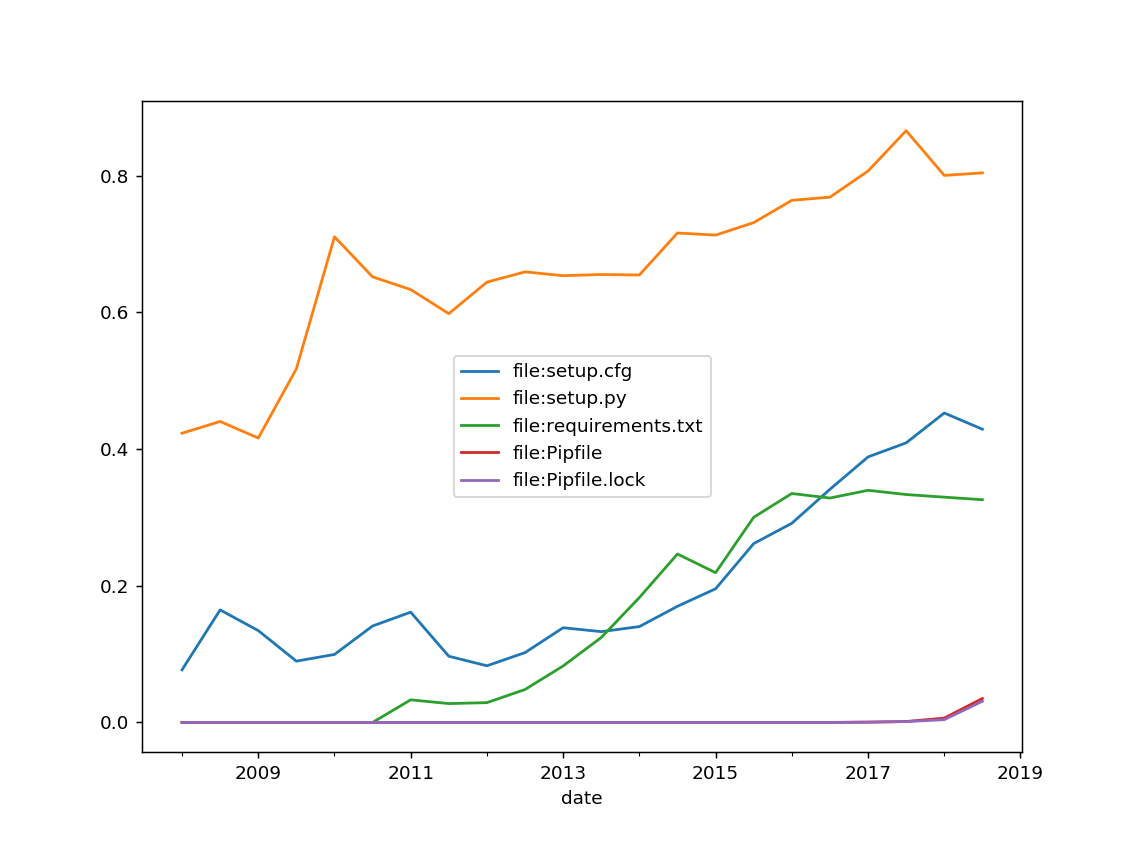
Notes:
Nothing really interesting here :( We see the rise of Pipfile, but still can't say much about it...
Requirements
For dependency managment I've seen a lot of philosophies. and it really depends on "are you packaging", "is it an app or a library", …
Digression
The future
PEP 517 and PEP 518
[build-system]
requires = ["flit"]
build-backend = "flit.api:main"
Notes:
are introducing a way to completly remove setuptools and distutils from being a requirement, it make them a choice:
Tests
tests = (raw_data.groupby('test_engine')
.resample('Y')['test_engine']
.size()
.unstack()
.T
.fillna(0)
.apply(lambda line: 100 * line / float(line.sum()), axis=1)
.plot())
Tests
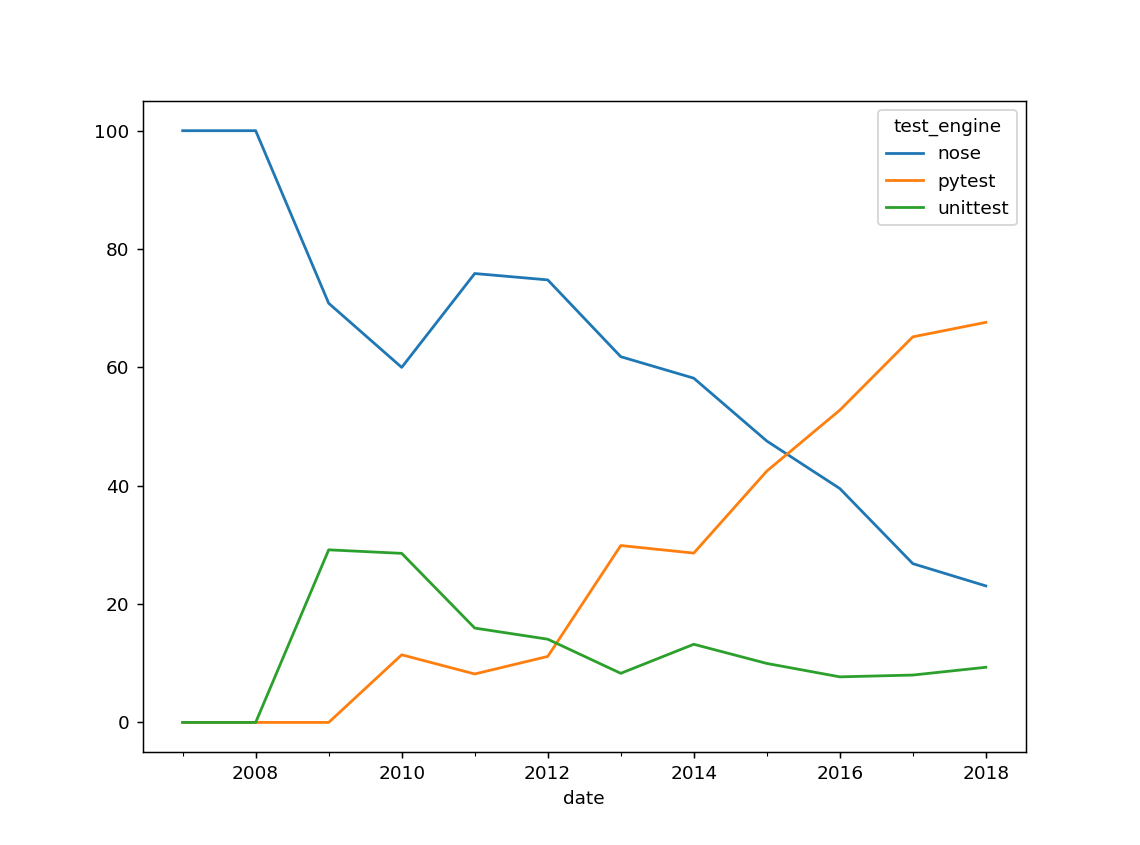
Notes:
Sorry nose.
Documentation directory
docs = stats['dir:doc/', 'dir:docs/'].mean().plot()
Documentation directory
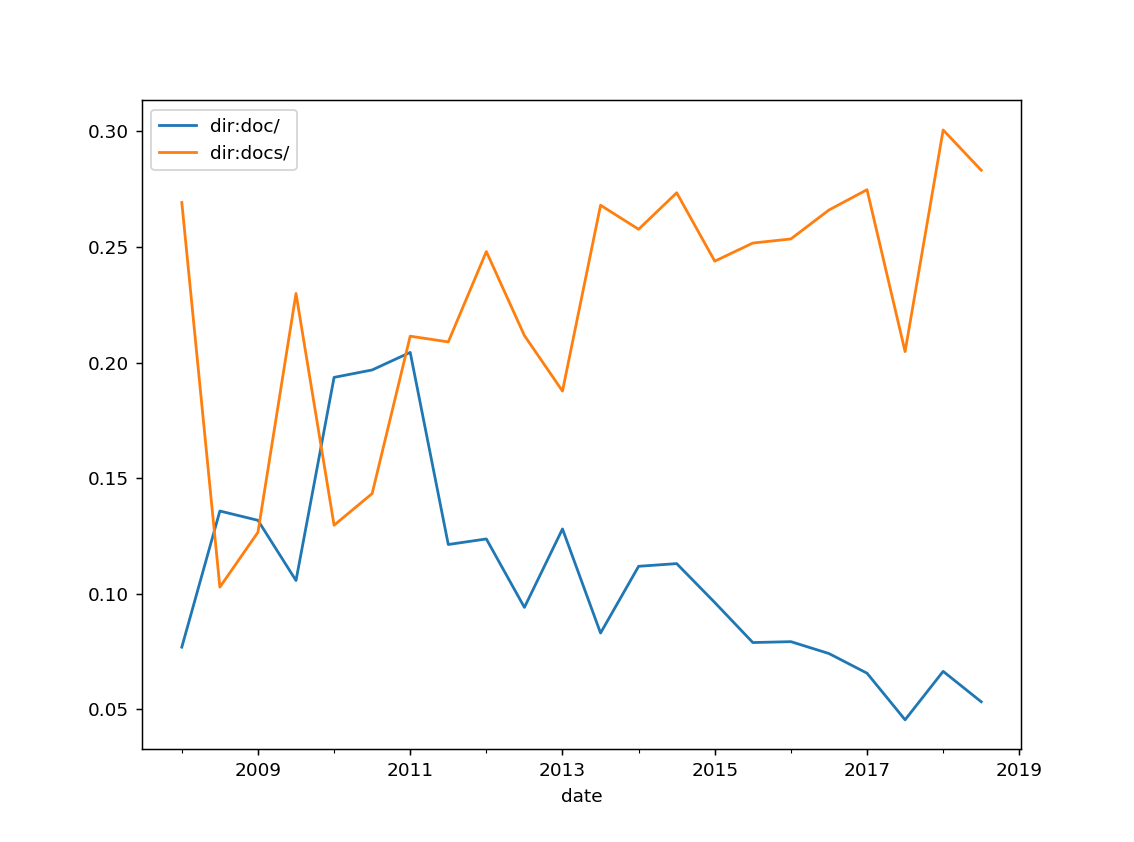
Note: Some of you are not documenting at all!
Concensus emmerged around 2011 towards docs/ instead of doc/, let's stick to it (please, please, no Docs/, I see you, cpython).
src/ or not src/
src = pd.DataFrame(stats['dir:src/'].mean()).plot()
src/ or not src/
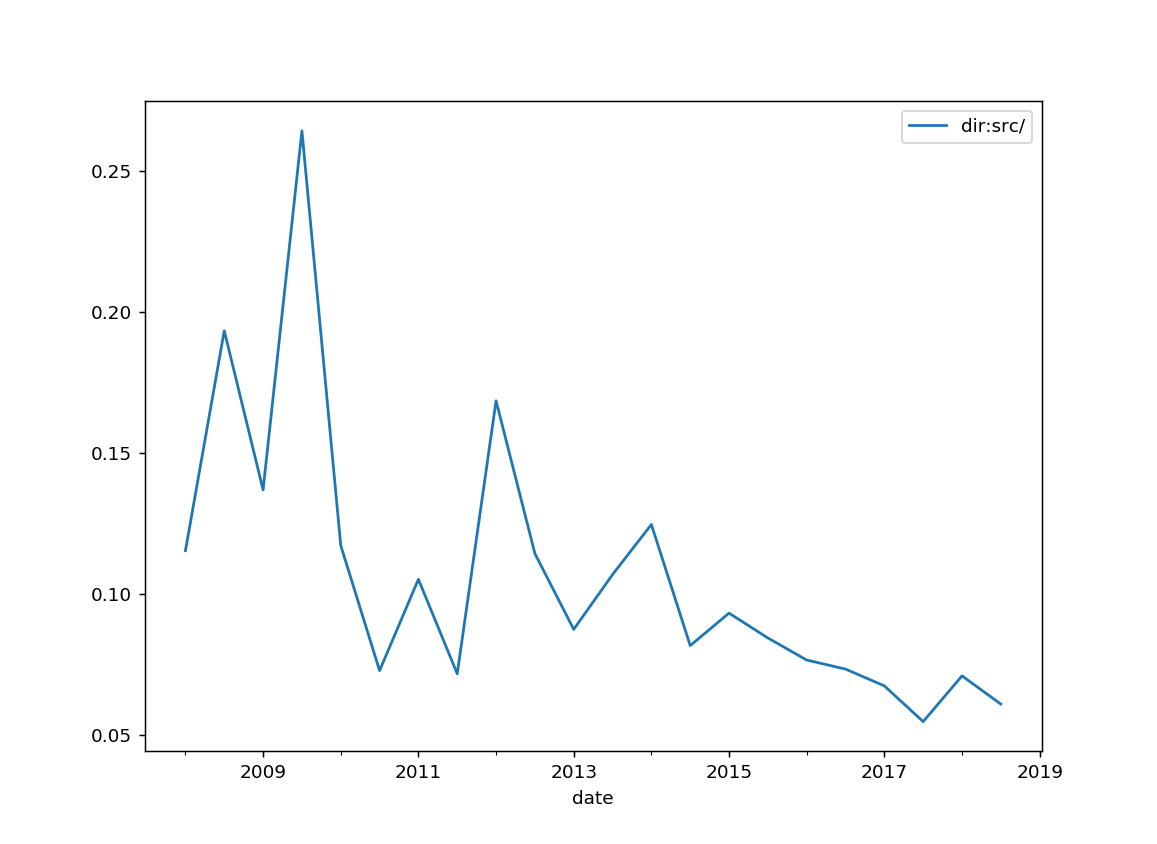
Notes:
This one was slow, but the concensus is to drop the use of a src/ directory.
I used it a lot, convinced it would allow me to spot earlier an import bug ("." being in PYTHONPATH but not "src/"). But that's way overkill for a small win.
tests/ or test/?
has_tests = stats['dir:tests/', 'dir:test/', ].mean().plot()
tests/ or test/?
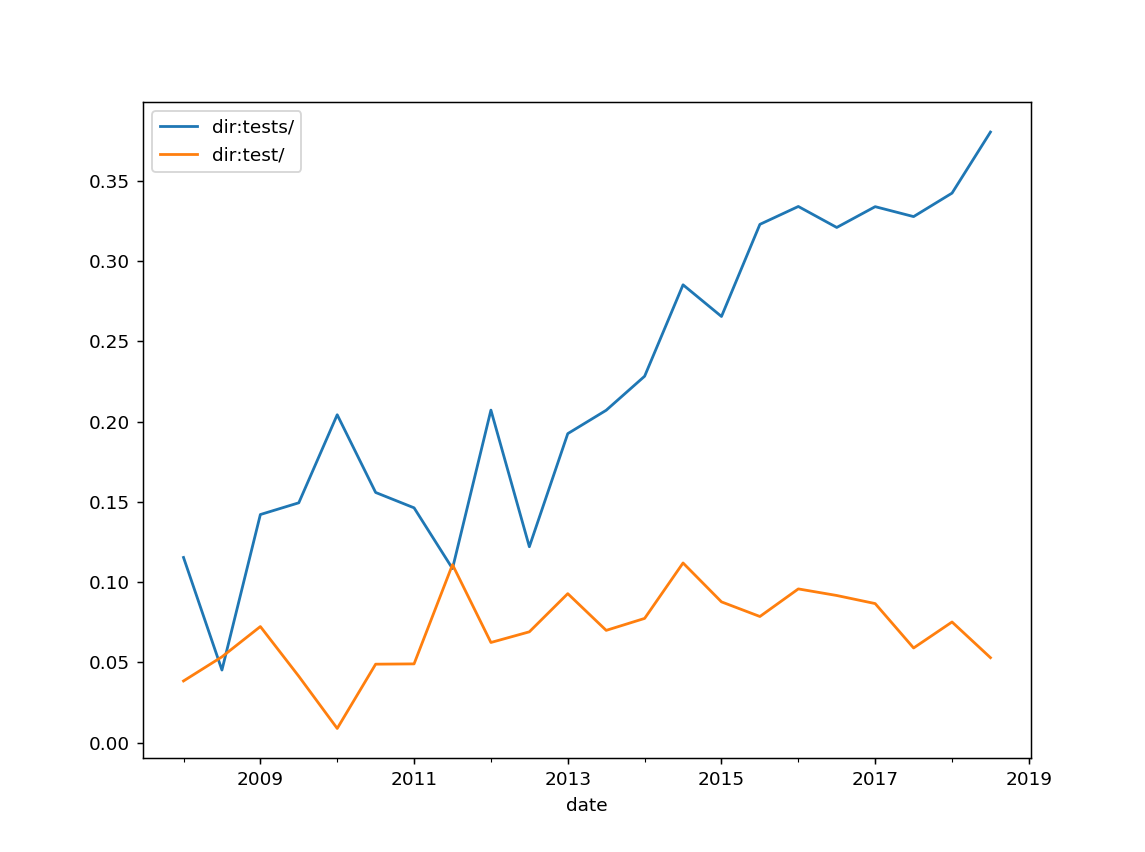
Note: First thing I see... Not everyone is writing tests.
I'm glad the concensus is as for docs/ and doc/, plural clearly wins. I bet it's semantically better, as the folder does not contain a test, but multiple tests.
pyproject.toml: to declare dependencies of your setup.py
Shebangs
shebangs = (raw_data.loc['2008-01-01':,raw_data.columns
.map(lambda col: col.startswith('shebang:'))].sum())
top_shebangs = shebangs.sort_values().tail(4).index
shebangs_plot = (raw_data.loc['2008-01-01':, top_shebangs]
.fillna(value=0).resample('6M').mean().plot())
Shebangs
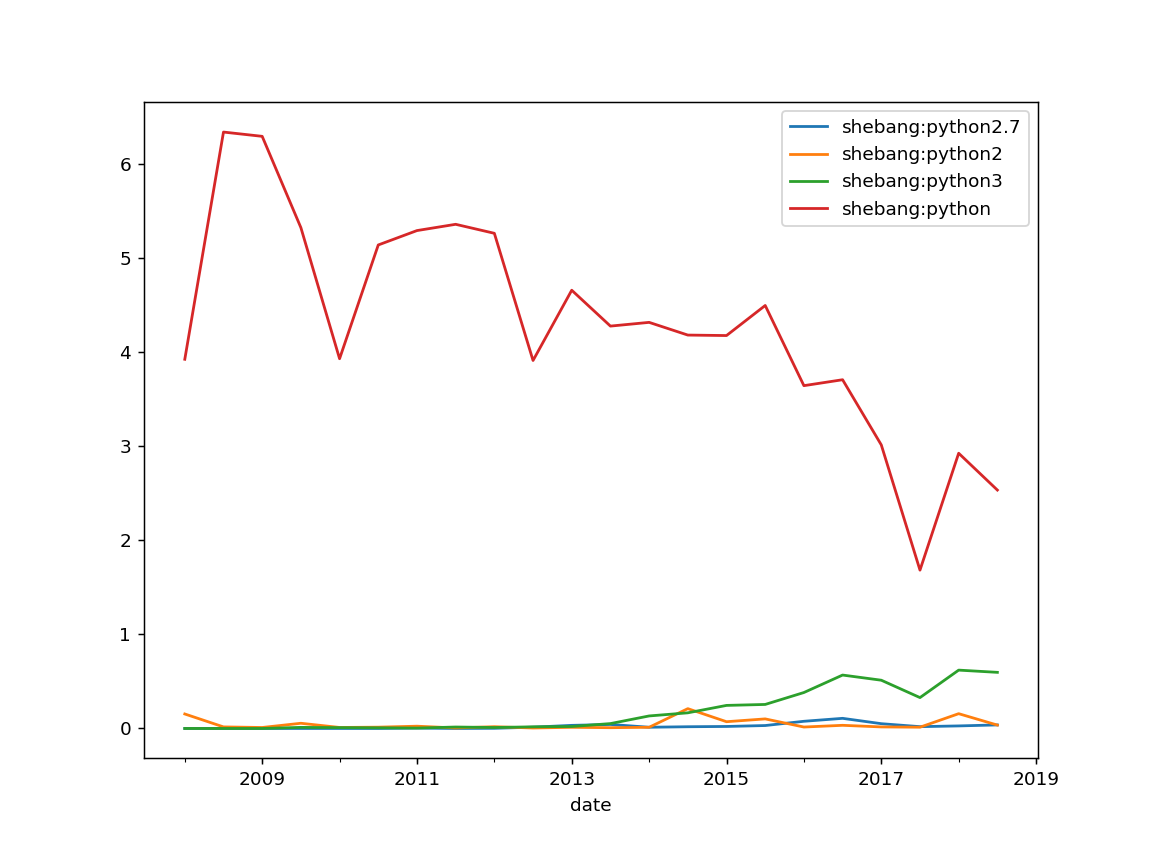
Notes:
I'm glad there's not so much #!/usr/bin/env python2.7 here.
I'm not sure it's a good idea to specify a version in the shebang, but...
Licenses
top_licenses = raw_data.groupby('license').size().sort_values().tail(10)
licenses = (raw_data.groupby('license')
.resample('Y')['license']
.size()
.unstack()
.T
.fillna(0)
.loc[:, list(top_licenses.index)]
.apply(lambda line: 100 * line / float(line.sum()), axis=1)
.plot())
Licenses
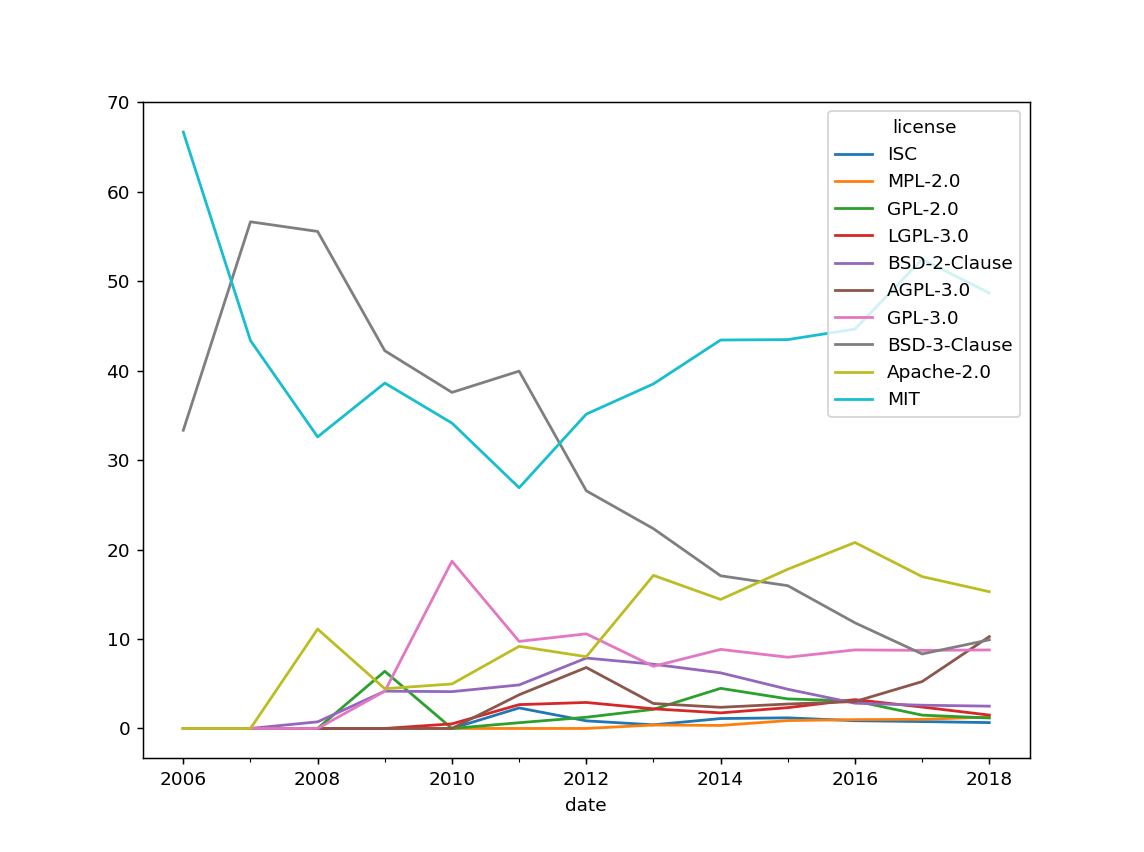
Digression
Questions?
- julien@python.org
- Twitter @sizeof
- https://mdk.fr